Enable high-quality digital experiences leveraging best practices such as Material.
Enable shipping new features faster with OOTB libraries such as Material-UI React UI.
First class Typescript build support
Opinionated: automated way to perform repetitive tasks e.g.: via CLI commands such as create-plugin, start-plugin, start-dev-plugin
Reusable: ability to reuse the same pattern to inject data in common UI components such as Lists, Tables and others (e.g. here).
More specifically, similar data and properties to pass data between components.
Ability to fetch data from external sources, incl. popular API backends such as GraphQL
Built in authentication, authorisation and test framework with mainstream frameworks, e.g.: passport.js, jest, etc
About the structure:
a plug-in should be deployable as a self-contained webapp
A plug-in should contain one or more components.
A component should have ideally:
No more than one UI component to increase reusability.
No more than one data source/back end, which can be provided by:
A micro-service within the same domain or
External source via service proxy (like Nginx, HAProxy, etc.) to work around CORS policies.
image taken from Spotify’s backstage architecture page.
Notes
The following items are inspired in Spotify’s backstage per instructions here:
Req #4 (here), whcih describes the commands yarn install, yarn create-plug-in and yarn dev. Which is akin to ng new <app_name>, ng serve –open and ng generate component <component_name>
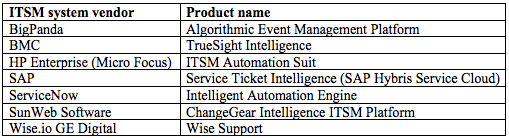
Before talking about tools one should start to define a challenging question or problem to solve. Then you need sample data because in ML a function (called Model, i.e. the algorithm) is developed, trained and evaluated for accuracy using sample data. There are already well-established use cases in the ML space, to the point that academics (sample thesis here) and ITSM system vendors already feature ML capabilities as per summary below (extracted from here).
ML capabilities for ITSM fall within the following categories:
Supervised ML classification
Automatic ticket priorization (i.e.: predictions about the likely assigned ticket priority).
Automatic ticket categorization / triage (a.k.a. Sentiment analysis of users product reviews example here– and github classification –here-).
Unsupervised ML clustering problem assigning a new ticket to a cluster of known solutions
Automatic ticket solution
Predictions about how long it will take to resolve the ticket*.
Below there are some documented use cases of Supervised ML classification:
Create a model for automatic support tickets classification: Endava and Microsoft developed a POC to automatically convert emails into tickets and assign values to properties like: ticket_type, urgency, impact, category, etc. The anonymized data set of 50k records is here, the source code is here. They applied multiple steps including the below.
Data Preparation (a.k.a. Transformation): like Select required columns from the dataset, clean missing values, remove stop words, remove duplicate char, replace numbers, convert to lower case, stem words etc. Their distribution of values for most of columns to classify is strongly unbalanced but could not fix it with existing techniques (see techniques here).
ML Algorithms: to train models, Support Vector Machines -SVM- and Naive Bayes algorithms were tested. The ticket_type column was calculated using the best hyperparameters obtained with GridSearchCV (improved precision by 4%)
Results: for the tycket_type column, the precision was 98% in average.
Additional notes:
This example is also in the in the Azure AI Gallery, in that version they also use feature hashing/engineering to convert variable-length text to equal length numeric feature vector to reduce dimensionality and Filter based feature selection to get top 5000 features using the Chi-squared score function. Also the Split Data module to split data into Test and Training, as rule of thumb it can be divided into 70- 30 ratio for training and testing respectively.
Because one class which covers 70-90% of the data, the results for columns category, impact and urgency are completely rigged. The results for the column business_service are also flawed because a lot of classes that were not at all recognized.
Incident Routing: «Almost 30–40% of incident tickets are not routed to the right team and the tickets keep roaming around and around and by the time it reaches the right team, the issue might have widespread and reached the top management inviting a lot of trouble» (extracted from here, source code here).
Their Data processing Pipeline is made of the following stages: Data Preparation, calculation of feature vector of input data, ML Algorithm (in this case: CNN, RNN, HAN) and finally creation of Predictive Model to make label predictions.
Data Preparation: they classified the DataSet using Topic Modelling to make a labelled dataset and find the top categories of incidents. In Topic Modelling, each document is represented as a distribution over topics and each topic is represented as a distribution over words. Then NLTK** (Natural Language Toolkit / Python to work with human language data) Wordnet is used to find synonyms and WordNetLemmatizer is used get the root word. The list of words is converted to a dictionary and then to a bag-of-words model for LDA (Linear discriminant analysis) to find the 5 top topics, which are used to label the dataset. Then the resulting model is visualised with pyLDAvis.
ML Algorithms: the algorithms tested in the model include Recurrent Neural Network (RNN) and Long Short Term Memory networks (LSTMs). LSTMs is applied to use Keras (and more specifically Keras Tokenizer class).
Classification of incoming ticket: the distributions of classes are strongly skewed towards the first three of the seven ticket categories (e.g.: password reset). Ticket data are highly structured except for the symptom descriptions, so text analytics / data preparation phase is the most challenging part.
Data Preparation: records are vectorized using the «Term frequency-Inverse document frequency Tf-Idf«, which is a standard method for measuring the relative importance of a term within a textual structure.
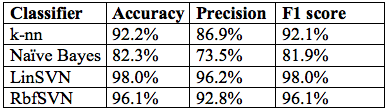
ML Algorithms (a.k.a. Modelling Phases): The classification algorithms trained include linear (LinSVM) and radial basis function SVM (RbfSVM), k-nearest neighbors (k-nn), and Naïve Bayes (NB). NB is used for text classification and SMS spam detection (similar to Data2Class, Delany, 2012).
Results:
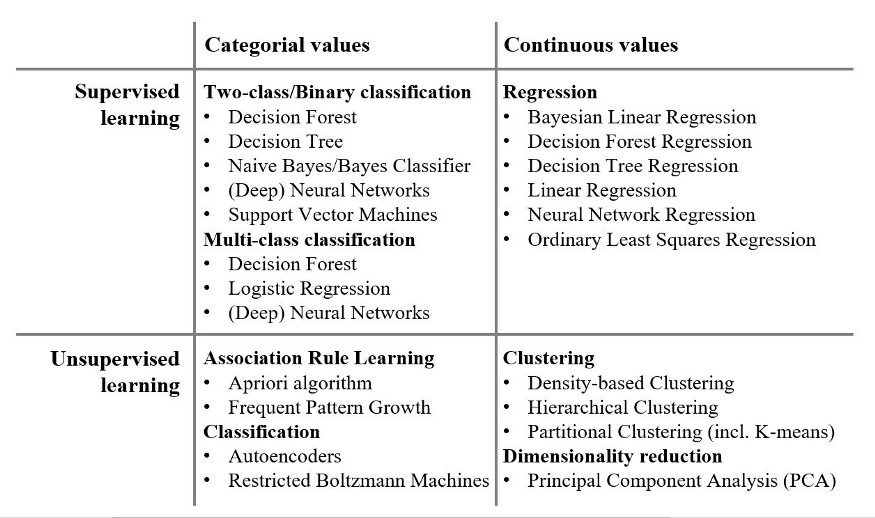
3 Widely-used ML algorithms structured by problem class
Data Science is not only for Data Scientists, Developers, BI Developers and BI analysts can also use AI/ML tools. In Data Science, the code is not the most challenging part. what is difficult is to find out which data and algorithms suits your use case. The resulting code is indeed very compact as per example below.
ML.NET is just another tool which makes easier to load data from a file or SQL and it provides lots of models.
4 Glossary
Confusion matrix: predicted VS actual classifications.
Feature vector: n-dimensional vector of numerical features that represent some object
Model Scoring/Evaluation: to evaluate a model the standard evaluation metrics Accuracy, Precision, and F1 score is used.
Pickle file: exported serialised model in python, including model name, hyperparameters and weights of the model.
Vector: a vector is a tuple of one or more values called scalars, e.g.: v = (v1, v2, v3). Vectors of equal length can be added, subtracted, multiplied, divided, etc. To define a vector in numpy:
Hadoop is a framework that facilitates software to store and process volumes of data in a distributed environment across a network of computers. Several parts make up the Hadoop framework, which includes:
Hadoop Distributed File System (HDFS): Stores files in Hadoop centric format and places them across the Hadoop cluster where they provide high bandwidth.
You can store in HDFS any file type. Some file types support queries like parquet, e.g. below:
parquetFile.createOrReplaceTempView(«parquetFile»)teenagers = spark.sql(«SELECT name FROM parquetFile WHERE age >= 13 AND age <= 19»)teenagers.show()
MapReduce Programming Model: This is a Hadoop feature that facilitates a batch engine to process large scale data in Hadoop clusters.
YARN (Yet Another Resource Negotiator): A platform for managing computing resources within the Hadoop clusters.
Spark is a framework that focuses on fast computation using in-memory processing. Spark includes the following components:
Spark Core: it facilitates task dispatching, several input/output functionalities, and task scheduling with an application programming interface.
Spark SQL: Supports DataFrames (data abstraction model) that, in turn, provides support for both structured and unstructured data.
Spark Streaming: This deploys Spark’s fast scheduling power to facilitate streaming analytics.
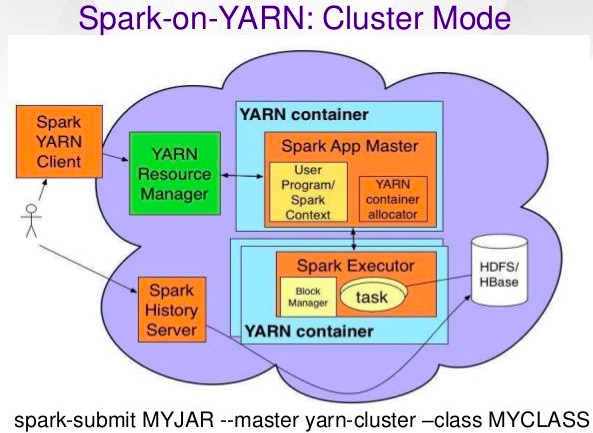
Spark can run on EC2, on Hadoop YARN (i.e.: spark data processing jobs run on yarn), on Mesos, or on Kubernetes.
Hadoop is usually bundled with the following components:
Now the concepts:
hadoop client allows you to interact with the file system and it uses kerberos to authenticate, sample commands (hadoop fs can talk to different file system, hdfs can only talk to HDFS):
To list version: hadoop version (output.: Hadoop 3.0.0-cdh6.2.1)
Command to see root folder name: hadoop fs -ls -d
Command to list directories: hadoop fs -ls
Command to list files in a directory: hadoop fs -ls pattern
To copy a file from linux to hadoop: hadoop fs -put /path/in/linux /hdfs/path
hadoop command to list files and directories in root: hdfs dfs -ls hdfs:/
hadoop is usually secured with kerberos, some sample commands:
To delegate privileges to other user: pbrun user
To verify tickets use: klist
To list the obtained tickets: klist -a
To obtain and cache a kerberos ticket: kinit -k -t /opt/Cloudera/keytabs/whoami.hostname -s.keytab whoami/hostname -f@domain
Yarn is the cluster management tool.Sample command: yarn application -list
You can run apps in Spark using the Spark client OR self contained applications OR scripts.
Spark supports multiple programming languages, incl. Java, Python, and Scala.
pyspark is the python library for spark.
Spark has modules to interact via SQL or DataFrames or streaming.
Sample spark client commands:
spark-submit –version (e.g.: version 2.4.0-cdh6.2.1)
To run spark-shell and load class path: spark2-shell –jars path/to/file.jar
The following is a summary of recommendations from the book Architecting Data Lakes (warning: this book has a good share of references to Zaloni’s Data Platform -which is a bit annoying- but it is still good reading material)
There should be at least 5 zones with the following functions:
Transient Landing Zone: with managed ingestion (i.e.: when metadata is known ahead of time), this is where the following functions take place: versioning, basic data quality checks (e.g.: range checks, integrity checks, etc.), mask/tokenise data and metadata capture.
Raw Zone: this is where data is added to the catalogue and each cell is tagged according to how “visible” it is to different users to specify who has access to the data in each cell.
Trusted Zone: in this stage more data cleansing and data validations are performed. Also data is usually grouped into two categories: master data and reference data (new single version of truth).
Refined zone: in this zone data is transformed and standardised to common format to derive insights as per LOB’s reqs. Data is watermarked by assigning an unique ID for each record (at either the record or file level). Data is exposed to consumers with appropriate role based access.
Sandbox zone: in this area data is exposed for is for ad-hoc exploratory use cases and the result can go back to the Raw Zone.
Special functions:
Functions outside this process:
Life-cycle: to move from hot to cold storage.
Functions across all steps:
Data lineage.
Detect whether certain streams are not being ingested based on the service-level agreements (SLAs) you set.
Bonus point: another interesting book on this topic is «Data Lake for Enterprises: Lambda Architecture for building enterprise data systems».
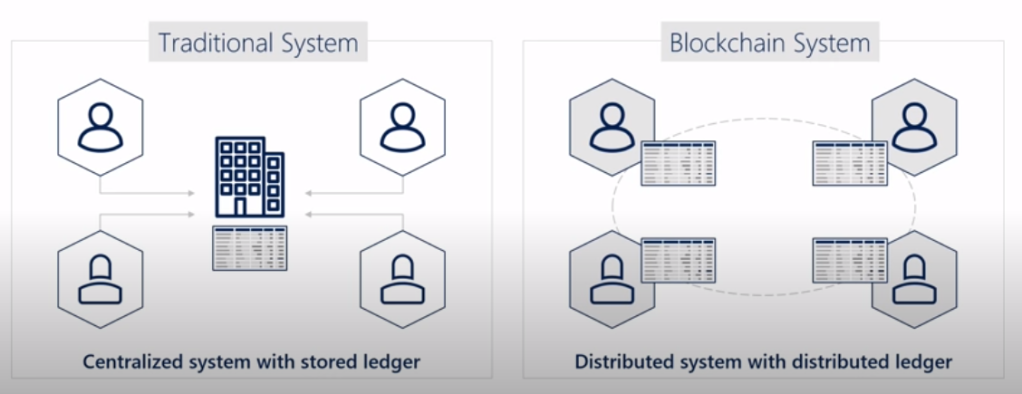
Since everyone in the network/Consortium has an identical copy of the blockchain then you must:
Minimize the set of concerns that a single contratc must handle, i.e.: Only do only the most necessary work in the blockchain.
Keep complex agregate of inferred state calculations off chain.
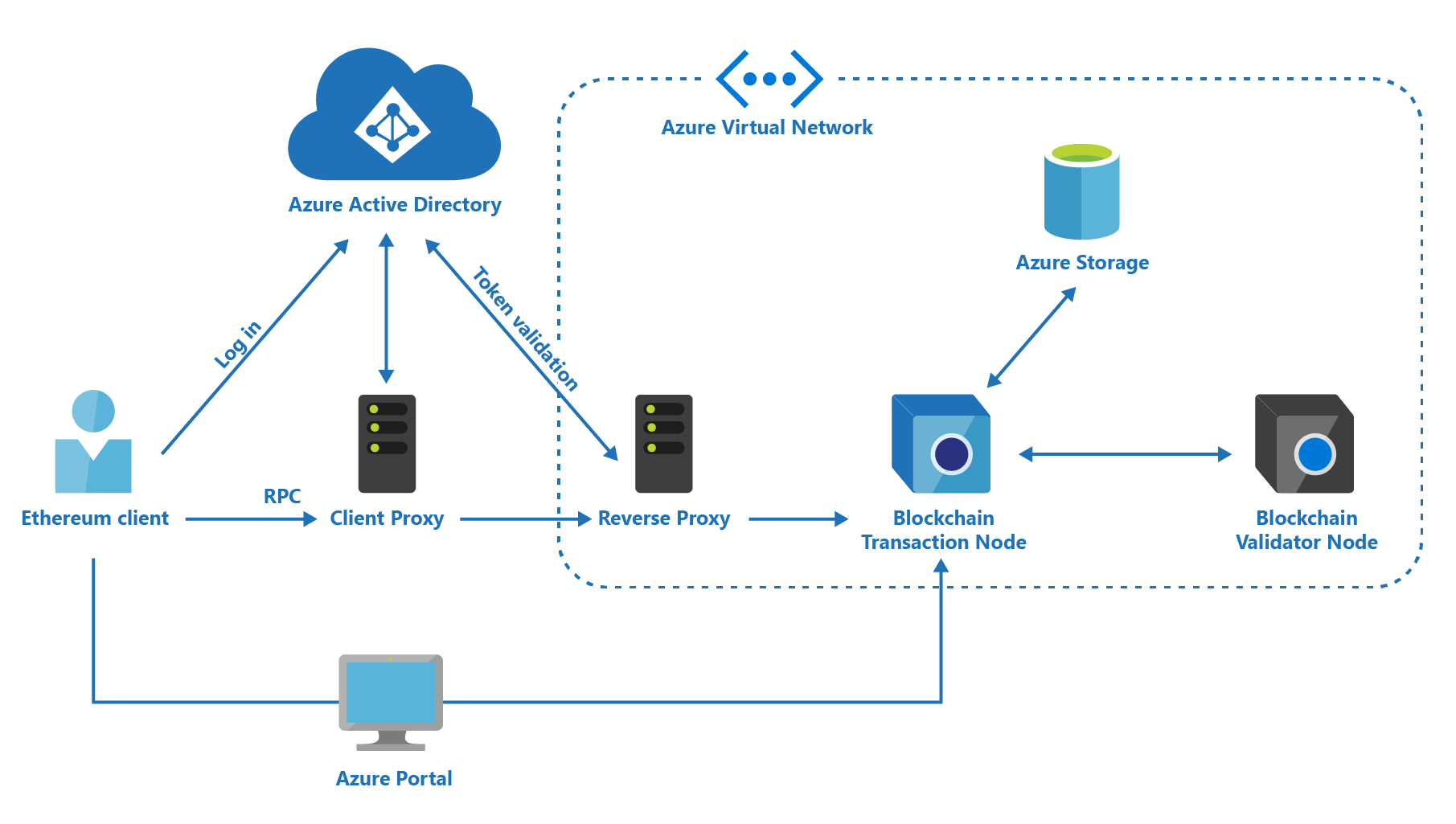
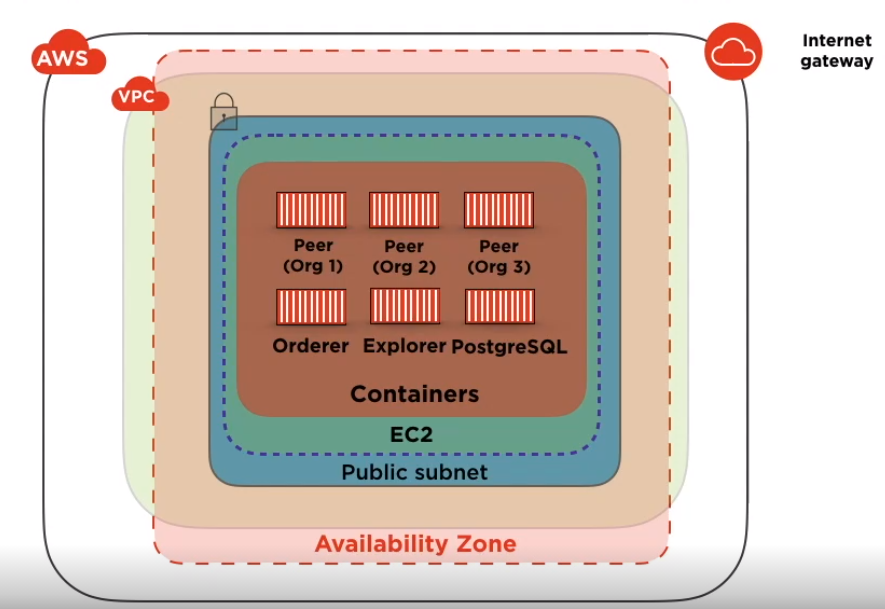
Managed Blockchain Ethereum infra in AzureHyperledger Fabric on AWS (based on containers)
The data is both inmutable and cryptohraphicaphycally secure.
Dealing with the realities of how counterparties interact today.
Reduce settlement times and reduce costs tied to reconciliation.
Good Development Practices for DAPPs
Pick up one language to write Business Logic: Solidity for Ethereum, Kotlin/Java for Corda (Flow/Contract) and NodeJS/Go for Hyperledger Fabric (Chaincode).
Write contractc which can be tested with few or no dependencies (low fan-out)
Two main public implementations of blockchain are bitcoin and ethereum. For enterprises and private networks the main two implementations are HyperledgerFabric (more info here) and Ethereum
Quorum: is an Ethereum-based distributed ledger protocol / platform that supports block chain transactions and contract privacy.
Consortium: network consensus / multiple organizations maintaining the network. There is a consortium Leader in private blockchain which sets up the initial ether.
Participants validate and store transactions.
Data is stored in a ledger, ledger can be updated only by network consensus. Accounts can vote only once.
Distributed consensus is not a new topic. Products like HDFS, MQ, ZooKeeper / Kafka, Elasticsearch, etc already have implemented this form of data integrity. This approach addresses teh following challenges:
R3 Corda and HyperLedger Fabric use the Raft algorithm, now moving to BFT.
Everyone in the network has an individual identical copy.
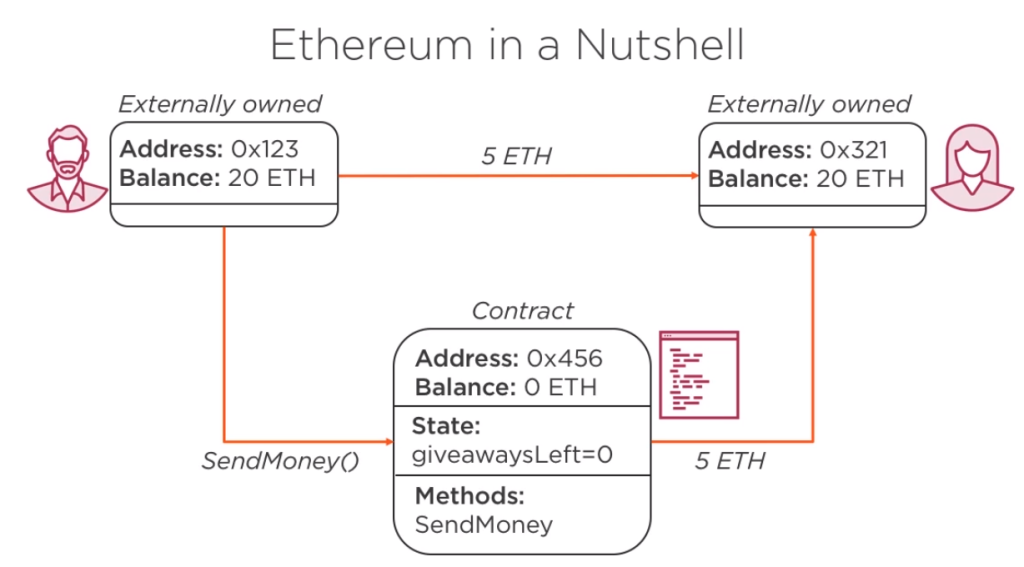
After a contract is mined (think like deployed and instantiated), you can interact with it.
«Gas» is what miners are paid for transactions.
MetaMask: chrome extension to transfer ether between accounts.
Bitcoin transactions are monetary, in Ethereum is executable code as well.
Blockchain forms a chain between two blocks using hashes (similar to a single linked list, where first node is called «genesis block» and «root node» in a linked list)
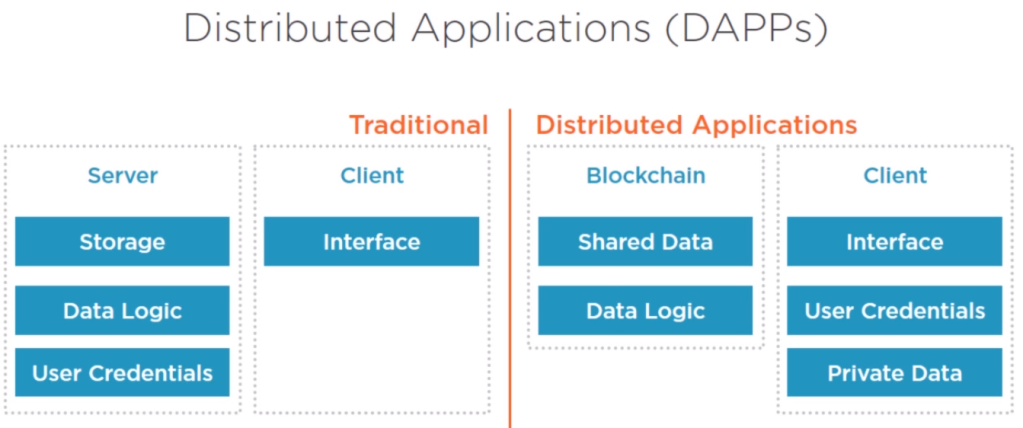
Distributed Applications (DAPPs): development and deployment approach in blockchain as per below images.
There are different types of clients for blockchain networks including full nodes, light nodes, and remote clients.
Ligth nodes don’t download the full blockchain, only the headers to validate the authenticity of the transactions.
The minimal setup is one transaction node (full node) and 2 validators (light node).
About Dev Tools:
To build smart contracts the following languages are mainly used: Solidity for Ethereum, Kotlin for Corda and Go for Hyperledger Fabric.
There are other alternatives to Solidity, e.g.: serpent, viper. Soidity is also supported by Bitcoin.
These languages compile to ethereum bytecode to run in ethereum nodes
There are many tools for Smart Contract development, incl.:
Truffle: set of tools to build, test and assist in smart contract and Dapp development.
TestRPC: in memory blockchain.
Ganache/Infura: personal ethereum blockchain to develop locally.
Hyperledger Besu is a popular Ethereum client
Remix: testing, debugging and deploying of smart contracts in the browser.
There are many libraries to interact with an ethereum network, incl.: web3js, nethereum, truffle, etc
About Smart Contract Development
Contracts have data and methods
Contrats can interact with people and people between people
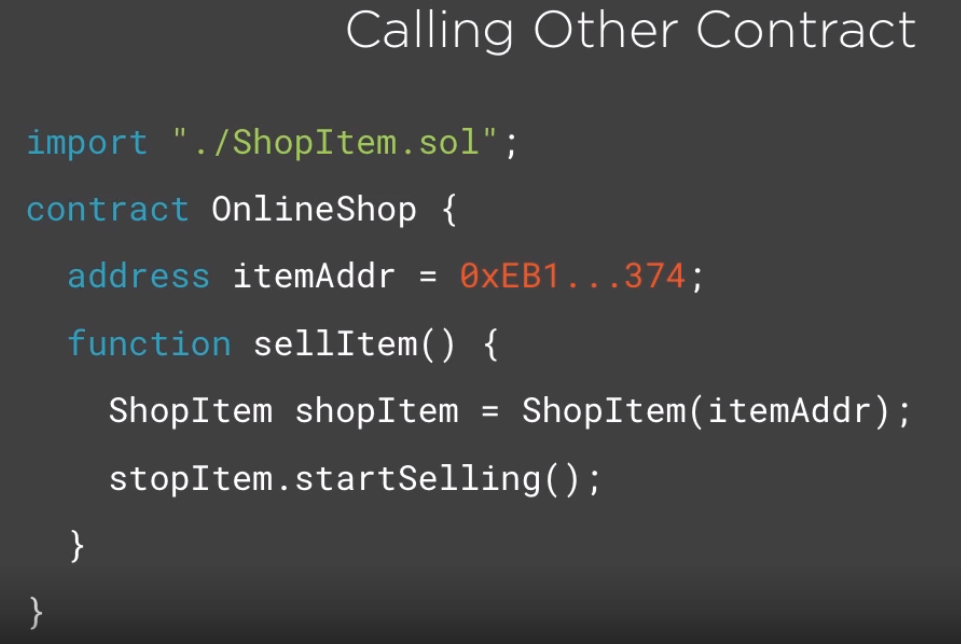
Any participant of the network can call contract functions and change state as per example below.
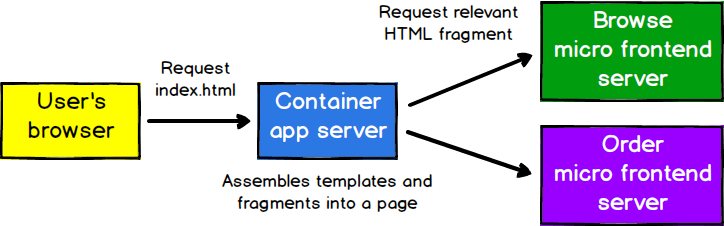
The idea is simple: You have *something* where you assemble micro-frontends servers. Each micro-frontend is similar to old school iframes. That *something* is usually a page container (Not a docker container!).
Many people argue that micro-frontends are not a thing, but just a new name for the good old component* model available in pretty much all UI frameworks long time ago (more on this discussion here).
But regardless of the conceptual definition, the question is: how do we implement this with modern frameworks?
Frameworks
There are multiple options, they all split a page into fragments which are then put together using routes or conditions (a.k.a. client site composition), just to mention some (grouped by level of abstraction):
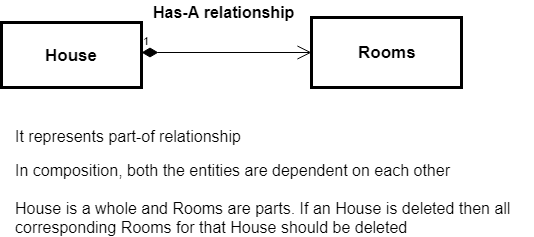
*Similar to the Composite View design pattern which is based in Composition. Composition is represented with a filled diamond. Composition involves «ownership», so in the example below a «House» has «Rooms».
The Generative Pre-trained Transformer 3 is the latest language version which uses Deep learning to produce human like text. GPT-3 was created by the OpenAI Lab (which has Elon Musk as one of the founders).
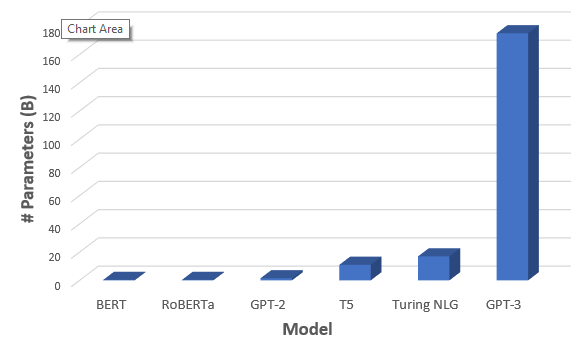
The main thing about it is that supports 175 billion machine learning parameters. Each parameter value define how the algorithms behave. Just for comparison, the most advanced language of this type was Microsoft’s Turing NLG, with *only * 17 billion params as per graphic below.
Turing NLG was capable of answering questions like «When did WW2 end?» and it was also capable of generating compplex summaries as per docummentation here.
On another hand, GPT-3 was trained with public information from internet, which means is capable of translating text, generating news articles and a range of applications which can be found here: https://gpt3examples.com/#examples
One of the coolest examples I found it’s about creating AWS automation (with OpsWorks, which is based on Chef or Puppet) from the following sentence in plain English «create, deploy, list, and delete any services on AWS».
I have a Motorola Focus 66-b camera
Today I was researching how to connect directly to this IP camera. Initially this seemed possible as per links below:
Despite the initial high expectation about communicating with the camera via RTSP it seems Motorola decided to block it and force users to use their app hubble instead 😦