I have noticed that many people are not familiar with Spark tools, so I wanted to put together few simple but important concepts about Spark below.
Firstly, some definitions: (extracted from here):
- Hadoop is a framework that facilitates software to store and process volumes of data in a distributed environment across a network of computers. Several parts make up the Hadoop framework, which includes:
- Hadoop Distributed File System (HDFS): Stores files in Hadoop centric format and places them across the Hadoop cluster where they provide high bandwidth.
- You can store in HDFS any file type. Some file types support queries like parquet, e.g. below:
- parquetFile.createOrReplaceTempView(«parquetFile»)teenagers = spark.sql(«SELECT name FROM parquetFile WHERE age >= 13 AND age <= 19»)teenagers.show()
- You can store in HDFS any file type. Some file types support queries like parquet, e.g. below:
- MapReduce Programming Model: This is a Hadoop feature that facilitates a batch engine to process large scale data in Hadoop clusters.
- YARN (Yet Another Resource Negotiator): A platform for managing computing resources within the Hadoop clusters.
- Hadoop Distributed File System (HDFS): Stores files in Hadoop centric format and places them across the Hadoop cluster where they provide high bandwidth.
- Spark is a framework that focuses on fast computation using in-memory processing. Spark includes the following components:
- Spark Core: it facilitates task dispatching, several input/output functionalities, and task scheduling with an application programming interface.
- Spark SQL: Supports DataFrames (data abstraction model) that, in turn, provides support for both structured and unstructured data.
- Spark Streaming: This deploys Spark’s fast scheduling power to facilitate streaming analytics.
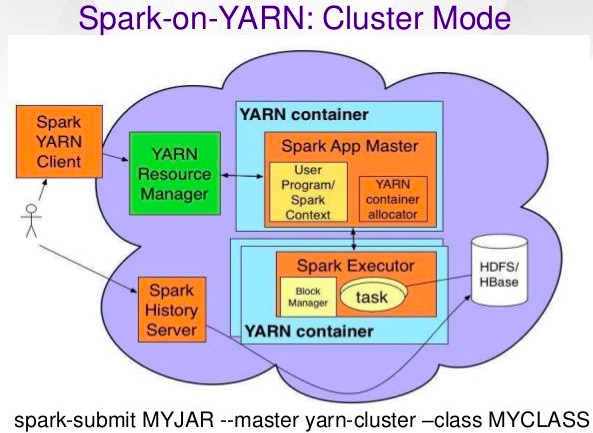
Spark can run on EC2, on Hadoop YARN (i.e.: spark data processing jobs run on yarn), on Mesos, or on Kubernetes.
Hadoop is usually bundled with the following components:

Now the concepts:
- hadoop client allows you to interact with the file system and it uses kerberos to authenticate, sample commands (hadoop fs can talk to different file system, hdfs can only talk to HDFS):
- To list version: hadoop version (output.: Hadoop 3.0.0-cdh6.2.1)
- Command to see root folder name: hadoop fs -ls -d
- Command to list directories: hadoop fs -ls
- Command to list files in a directory: hadoop fs -ls pattern
- To copy a file from linux to hadoop: hadoop fs -put /path/in/linux /hdfs/path
- hadoop command to list files and directories in root: hdfs dfs -ls hdfs:/
- hadoop is usually secured with kerberos, some sample commands:
- To delegate privileges to other user: pbrun user
- To verify tickets use: klist
- To list the obtained tickets: klist -a
- To obtain and cache a kerberos ticket: kinit -k -t /opt/Cloudera/keytabs/
whoami.hostname -s.keytabwhoami/hostname -f@domain
- Yarn is the cluster management tool.Sample command: yarn application -list
- You can run apps in Spark using the Spark client OR self contained applications OR scripts.
- Spark supports multiple programming languages, incl. Java, Python, and Scala.
- pyspark is the python library for spark.
- Spark has modules to interact via SQL or DataFrames or streaming.
- Sample spark client commands:
- spark-submit –version (e.g.: version 2.4.0-cdh6.2.1)
- To run spark-shell and load class path: spark2-shell –jars path/to/file.jar
- To run the program -> :load example.scala
- Spark supports multiple programming languages, incl. Java, Python, and Scala.
- To connect to hive using beeline:
- beeline -u «jdbc:hive2://server:10000/;principal=hive/server@domain;ssl=true»
- SHOW DATABASES;
- use db;
- use tables;
Javier
Thanks,

Deja un comentario